
🔎 Admin console: Easy Print & Scan > Integrated Scanning
Integrated Scanning allows you to use the PaperCut Hive admin console to centrally create Quick Scan actions you want to display on the printers’/MFDs’ touchscreen. They can then be deployed across multiple printers in the organization, reducing training needs and end-user errors while providing a consistent user experience.
You can also add you organization’s data sources and create Quick Scan actions with capture fields on the MFD’s touchscreen that you can capture user input from. Simply upload your organization’s data sources to integrate client lists, project lists, and more.
Supported printer/MFD brands
- Epson
- Canon
- Fujifilm
- HP OXPd
- Konica Minolta
- Kyocera
- Lexmark
- Ricoh
- Sharp
- Toshiba
- Xerox
For more information. Please check the PaperCut Hive and Pocket supported printers here.
Which scan destinations are included?
PaperCut Hive currently supports 11 scan destinations:
- Box
- Dropbox
- Dropbox Business
- Evernote
- Google Drive
- OneDrive for Business
- OneDrive Personal
- pCloud
- SharePoint
- Shared Google Drive
Learn how to set a Quick Scan to email to enable:
Auto paper size and mixed paper size scans
In PaperCut Hive’s Integrated Scanning, when an admin creates a Quick Scan action, they can choose the paper size to be Auto, which applies to two use cases of how the original paper size is detected:
- auto paper size detection
- mixed paper size detection
Use cases supported by each brand
Auto paper size detection | Mixed paper size detection | |
Epson | ❌ | ❌ |
Canon | ❌ | ❌ |
Fujifilm | ✔️ | ✔️ |
HP | ❌ | ✔️ |
Konica Minolta | ❌ | ❌ |
Kyocera | ❌ | ❌ |
Lexmark | ✔️ | ✔️ |
Ricoh | ✔️ | ✔️ |
Sharp | ✔️ | ✔️ |
Toshiba | ✔️ | ✔️ |
Xerox | ❌ available for eSF devices* | ❌ available for LeSF devices* |
How auto paper size detection works
Paper size detection relies on the physical sensors of the printer. The printer itself must have auto paper size detection as a native feature so that PaperCut Hive can map its Auto feature to the printer’s native auto paper size detection capability.
Benefits of auto paper size detection
A user may feed documents of any paper size into the MFD and it will detect them to produce a PDF with the right page sizes.
The advantage is that it saves the user from manually having to choose the paper size and orientation of the document being scanned.
For example, if the user feeds an A4 document in a scan job, and then a Legal size document in the next job and the Auto paper size is selected for both jobs, there are no steps for them to select the paper size and paper orientation.
Auto detection of mixed paper size scans
These are scan jobs where the user feeds different paper sizes within the same scan job, for example, Letter + Legal + Tabloid, or A3 + A4. When PaperCut Hive’s Auto paper size setting is used, the scan PDF shows pages without cut-off contents.
Printer processing might be longer since the printer has to analyze the size of each sheet of paper in the scan job.
Peculiarities by brand
Ricoh and Sharp
Some brands, like Ricoh and Sharp, have each PDF page size correspond to each physical paper sheet scanned.

HP OXPd
HP produces different outputs depending on the feeding source.
HP from the document feeder | HP from the glass |
All the pages in the output PDF are output to the maximum scannable area.
| Each page of the PDF matches the original paper size.
|


When not using Auto: What happens when the user selects the wrong paper size during scanning?
This applies for brands that don’t support Auto paper size in PaperCut Hive Integrated Scanning.
The paper size that the user selects tells the printer what the scanning area size needs to be. So if the user selects the wrong paper size, the scan output PDF pages will be the wrong size and not accurately reflect the scanned pages.
ISO examples: metric paper sizes
- If a user scans an A3 document but has A4 selected in the scan setting, the PDF will have A4 pages with the A3 contents cut in half, since A4 is half of an A3.
- If a user scans an A4 document but has A3 selected in the scan setting, the PDF will have A3 pages with half of each page being blank, since A3 is double of an A4.
ANSI examples: American paper sizes
- If a user scans a Tabloid document but has Letter selected in the scan setting, the PDF will have Letter pages with the Tabloid contents cut in half, since Letter is half of a Tabloid.
- If a user scans a Letter document but has Tabloid selected in the scan setting, the PDF will have Tabloid pages with half of each page being blank, since Tabloid is double of a Letter.
Scan PDF compression
Use scan compression to reduce a scan’s PDF file size. This is useful when you need to send PDFs by email, and also reduces the amount of file storage required. Many organizations impose file size restrictions on email attachments, so the scanned PDF files need to be an email-friendly file size.
PaperCut Hive has 2 types of scan compression:
- Native - Compression performed in the printer. Available on only some brands.
- OCR Add-on - Compression performed in the cloud.
To prioritize file size reduction, PaperCut Hive uses lossy compression. Lossy compression suits a variety of situations where file size is a primary concern, and the quality of the document can tolerate some loss of detail or information.
You can find a full description and related configuration details in Configure Scan PDF compression.
Quick Scan Action capture fields in scanning
Capture fields are prompts in a Quick Scan that users complete to provide extra information about the document they are scanning. Capture fields are created by admins when they create the Quick Scan.
Capture fields in Quick Scans are useful for capturing metadata like invoice numbers, cost center details, department names, etc.
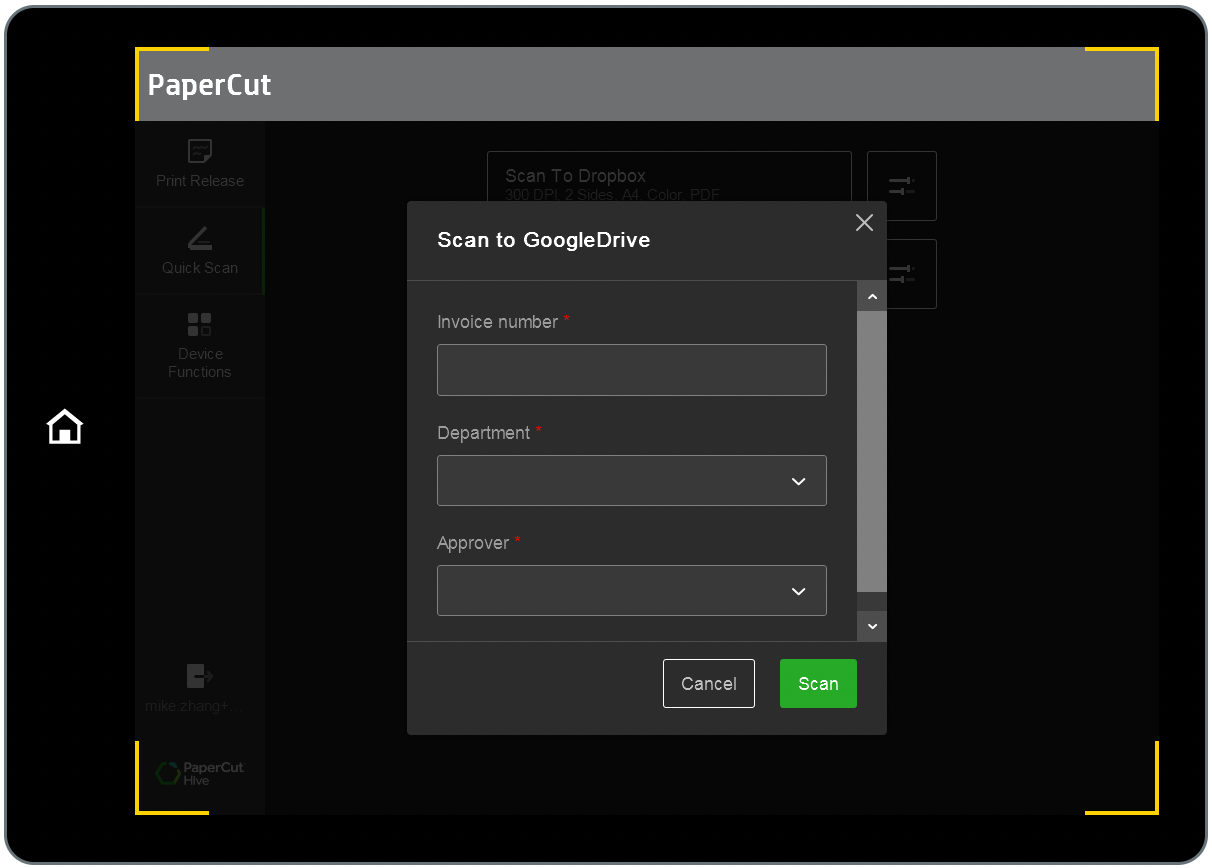
HP PageWide Color MFP P77960 touchscreen showing 3 capture fields.
The end-user enters the information into the fields when they’re doing the scan at the printer. Then during scanning, PaperCut Hive saves the information in a metadata file, like XML or JSON, and sends it with the scan output file (usually a PDF) to the scan destination. The destination can be a cloud folder, like in Google Drive or OneDrive, or an email.
After the scan reaches its destination, 3rd-party software such as document solutions or practice software (like legal, medical etc) reads the user-provided metadata and moves the scan file through a workflow.
You can find a full description and related configuration details in Configure Quick Scan capture fields.
Comments