
Our team has been using Google Cloud Datastore extensively as a part of our PaperCut Views product.
We have found ourselves needing to migrate data from Datastore to BigQuery periodically so we can analyze them better. Unfortunately, the process of migrating this data is quite painful, as it requires manually exporting and importing the data.
Thankfully, now we are using Google Cloud Dataflow to do so.
In this article, I would like to share the problems we had before when we wanted to run a migration and describe how Google Cloud Dataflow now helps us to do it much easier with a few brief examples.
Motivations
Since our application data is mostly stored in Cloud Datastore, we had to frequently move such data across to Google BigQuery so we could get better analytics and insights.
This could be done manually by exporting the Datastore Entities to a Google Cloud Bucket folder, and then importing them into Google BigQuery tables. However, when the size of the data is big, this process can take some time and requires someone to be present to manually execute the migration steps.
We wanted to have something less developer dependent, and so we came up with an automatic way of migrating the data using Google App Engine Task Queue. The App Engine endpoints trigger the tasks to fetch Datastore Entities in certain batch size and process them.
After that, they re-queue themselves with next cursors to continue to process next batched entities until it completes. With this approach, we were able to automate data migration tasks embedded in our apps.
Despite we achieved our purpose of making an automatic migration, we didn’t feel completely happy with it because every time we wanted to do it, we had to deploy our application including the migration tasks to production.
Also when the data is big, it could take some time to finish and the feedback loop was long if we wanted to see whether all records were correctly migrated.
When Google Cloud Dataflow was released, our inconvenients encouraged us to jump into it hoping that it will help us running the data migration easier. After using it for some time, we feel very happy with it, since it tackles all of our pains when it comes to data migration and transformation.
What is Google Cloud Dataflow?
Google Cloud Dataflow is one of the fully managed services provided by Google, aimed to process a large volume of data. It can be seen as ETL (Extract, Transform, Load) tool in GCP.
Most of ETL tools run on premise basis within the organization infrastructure and are usually used for building data warehouses extracting data from the databases in the systems and transforming it to various format of data and putting them into the data warehouse for reporting and data analysis purposes.
Likewise, Google Cloud Dataflow is an ETL tool that enables users to build various pipeline jobs to perform migration and transformation of data between storages such as Cloud Pub/Sub, Cloud Storage, Cloud Datastore, BigTable, BigQuery etc in order to build their own data warehouse in GCP.
What is Apache Beam?
Google’s great decision to release Dataflow SDK as an open source project called Apache Beam has contributed a lot to help building batch and real time processing pipeline jobs.
Apache Beam is an unified programming model aiming to provide pipeline portability so that jobs could run on multiple platforms such as Apache Spark, Apache Flink and Google Cloud Dataflow.
Two languages are officially supported for Apache Beam, Java and Python. Spotify is also contributing by developing a Scala API for Apache Beam called scio. For this article, I will use some Java examples as it is the only language we have used so far.
Dataflow SDK is a sub set of Apache Beam SDK
Google Cloud Dataflow SDK is currently released with version 2.1.0 as of now and it is a subset of Apache Beam SDK. This makes sense because given that individual Apache Beam platforms would have unique options and features respectively.
Therefore, Google Cloud Dataflow for example, needs GCP related options and IO components like DatastoreIO or BigQueryIO whereas some other components in Apache Spark and Flink would not be needed for a job running on Google Cloud Dataflow.
Running in batch or streaming mode
A pipeline job could run either in batch or streaming mode on Google Cloud Dataflow.
A job running in batch mode is more suitable for processing bounded data such as data coming from Cloud Datastore or CSV files. Because of this, it is a great fit for one time data migration tasks.
On the other hand, a job in streaming mode keeps on running and receiving continuous unbounded data such as messages from Cloud Pub/Sub and eventually storing them into other storages potentially transforming the data as it arrives.
I will mainly talk about pipeline jobs in batch mode as we are focusing on data migration in this article.
Reading, transforming and writing through a pipeline
A pipeline job generally includes three types of steps: reading, transforming and writing. After new pipeline is created in a job, a source step is attached to the pipeline to read data, and a sink step is used to write.
There could be various transforming steps involved in the middle of the pipeline. The pipeline job for data migration would rather be simple as it reads from a source and puts the data directly into a sink even without transforming steps in some cases.
We have briefly looked at Google Cloud Dataflow, Apache Beam and pipeline jobs so far. If you want to understand them in more detail, I recommend you to visit the websites Google Cloud Dataflow and Apache Beam.
How Google Cloud Dataflow helps us for data migration
There are distinct benefits of using Dataflow when it comes to data migration in the GCP.
No-Ops for deployment and management
GCP provides Google Cloud Dataflow as a fully-managed service so that we don’t have to think about how to deploy and manage our pipeline jobs. For instance, pipeline jobs can be triggered from the local machine but they actually get deployed to the specific google cloud project and run from there.
Therefore, we can effortlessly repeat the procedure to get quick feedback as the jobs are deployed and run together as a single step.
Auto scaling for quick processing of lots data
Auto scaling of workers’ virtual machines for pipeline jobs are the most compelling feature that Google Cloud Dataflow provides to quickly process large volume data in parallel.
For example, from our experience of data migration, it took about 15 minutes to migrate around 40 million records from Cloud Datastore to BigQuery table.
Therefore, we no longer need to wait for days to confirm the migration results.
No longer gradual migration
Pipeline jobs can be run with “auto scaling” option enabled, which means that the jobs will parallelize the data processing as much as possible spawning new vms as needed.
Because of this, we don’t need to wait any longer with gradual migration approaches like using Google Cloud Task queue with iterable cursors.
Connection between various storages
Pipeline jobs are the centralized connection points between various storages allowing them to migrate data easily through the pipelines. There are many built-in I/O Components and transforms described in Apache Beam guide.
Practical examples of pipeline job
Let’s have a look at hands-on examples of a pipeline job that could be used for data migration from Cloud Datastore Entity (it could be any Datastore entity to be migrated.) to a BigQuery table (e.g. ex_updateversion) for data analysis purpose.
Migrating data from Datastore to BigQuery is fairly easy with a pipeline job thanks to the good DSLs support in Dataflow SDK. We also recommend to develop the pipelines using JDK 8 so that we can benefit from the lambda expression syntax in high level MapElements functions. For instance:
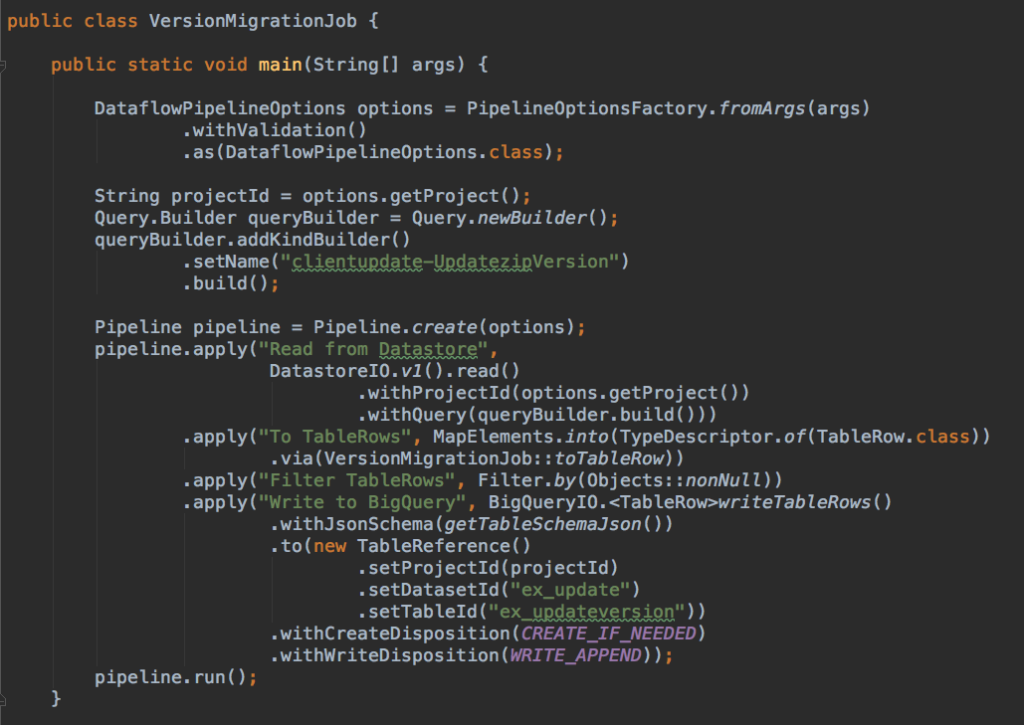
As you can see in the code above, a pipeline job basically has three parts: reading from source (Cloud Datastore), some transforming steps and finally writing to the sink, a BigQuery table as explained at the beginning of this article.
The job reads entities from Cloud Datastore using DatastoreIO.v1().read() and transforms them to BigQuery table rows (using MapElements.via() function) also it filters out null records from previous results. It eventually writes the table rows to the BigQuery table specified by using BigQueryIO.writeTableRows().
It can create a BigQuery table on the fly with a given table schema like the example above (withJsonSchema() method) and write the records appending them if the table exists (withCreateDisposition() and withWriteDisposition() methods)
Once a pipeline job is written, we can run it with DataflowRunner from the local machine to deploy and run it in GCP.
From the Dataflow menu in Google Cloud console, we can see a nice pipeline diagram of the running job:
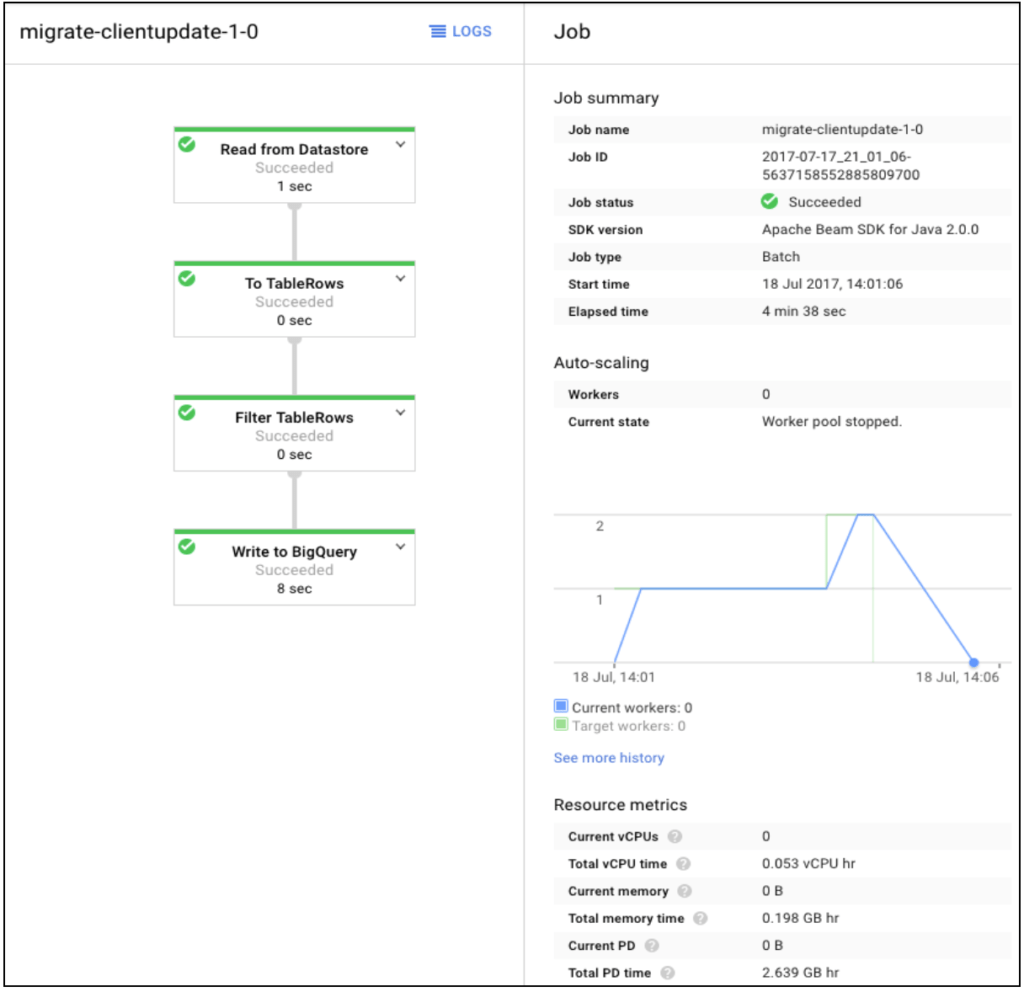
Monitoring the pipeline job with autoscaling workers in the graph is straightforward. We can drill down to the details from the diagram to see the actual steps underneath the pipeline job by checking the number of elements being added up in real time manner.
The error marks will be shown up on top if some problems are happening while the job is running and we can easily check and diagnose the errors and their stack traces in the stack driver logging thanks to the link from ‘LOGS’ above.
Migrating from one Datastore entity to multiple sinks
There are some cases in which we would need to migrate from a specific Datastore entity to multiple sinks like BigQuery tables or another Datastore entities. It is super easy with a pipeline job to do it. We can just add more sinks like this:
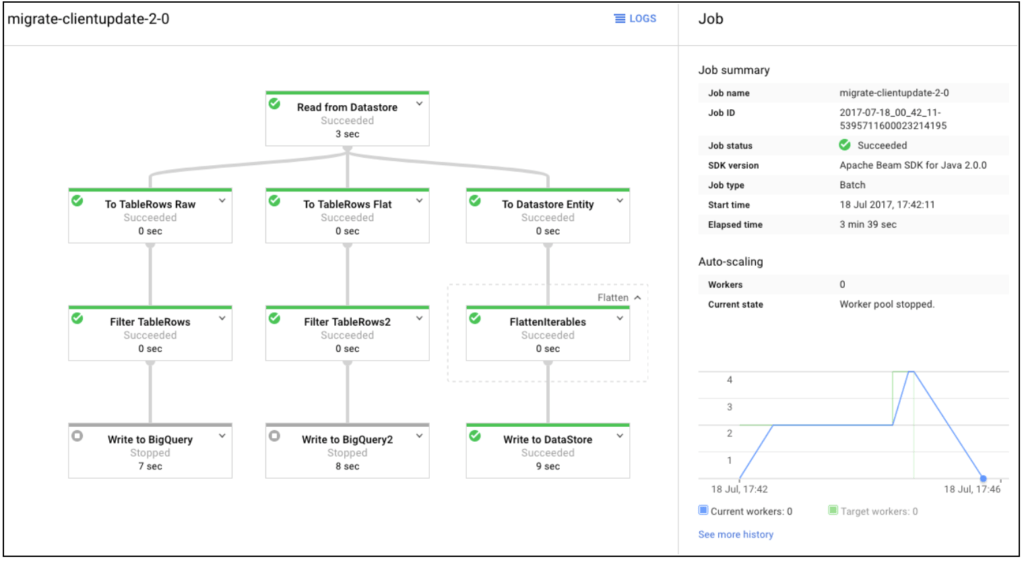
The console shows new pipeline diagram according to our pipeline job after the new job is deployed and run.
All workers and virtual machines to process a large volume of data behind simple source code and diagram are all taken care of by GCP to be auto-scaled so that we can focus on the pipeline logic in the job and don’t need to worry about the service infrastructure while the job is running. No Ops! as promised.
The pipeline job can also be monitored or managed by the gcloud dataflow command.
Migrating data in multiple independent branches
Last but not the least, it is possible to have multiple independent branches in a single pipeline job so that we can migrate data from various sources to sinks in parallel like:
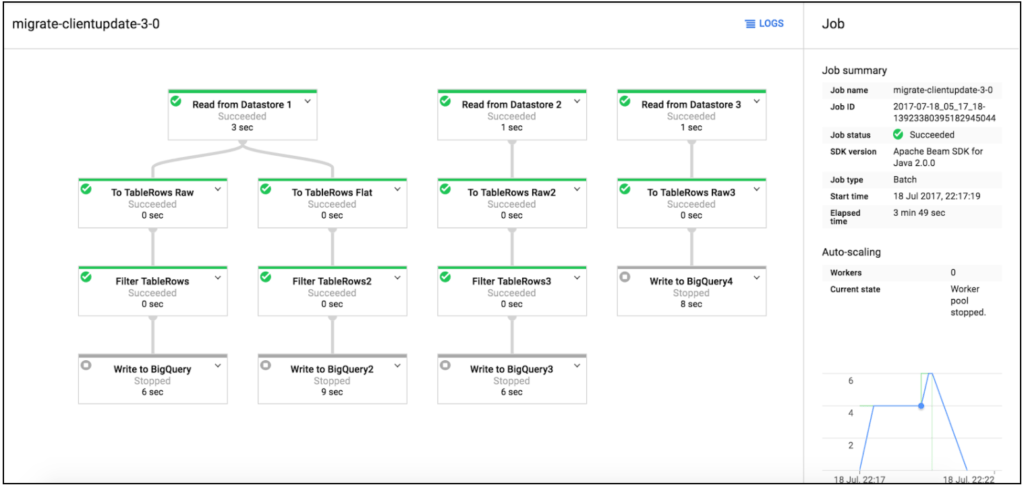
It does make sense to use a pipeline job as a migration tool for the tedious and manual duties. Google Cloud Dataflow, Google engineered service does better job than our hand-made ones and we would no longer need to worry about accidentally deleting production data by clicking ‘Delete’ button on Datastore admin console when doing backup.
Lessons learnt
I would like to share the lessons learnt from our experience using Google Cloud Dataflow so far.
Dataflow APIs and GCloud client APIs can get mixed up
Since Dataflow SDK needs some APIs for accessing storage in GCP, you might get confused when choosing which one to use.
Especially when dealing with Datastore, the Entity class from Dataflow SDK and the Entity class from Google Cloud Client are very similar to each other, we have to put extra attention to choose the right one since one is not compatible with the other.
Mapping Datastore Entities to BigQuery
Mapping Datastore entities to BigQuery could be a bit complicated if the entities have big nested structures. We recommend to have small Datastore entities with a structure as flat as possible. This is a good practice in general and comes even more handy when dealing with migrations to BigQuery.
Refer to this article for more reasons to better having smaller Datastore Entities.
Selecting best machine types
Out of memory error may occur due to the lack of the memory of Dataflow virtual machines while they are processing a large volume of data. Running the job a couple of times with different machine types and similar volume of production would help us to get confident for actual production migration.
Another consideration is that you can choose the best machine type for the data migration since the pipeline job runs once and it would be even better to complete as quick as possible.
You can specify ‘workerMachineType’ as a pipeline job option
Max number of workers
It may hit the quota limits of Streaming inserts for BigQuery table (Maximum 100,000 rows per second) if there are other pipeline jobs or BigQuery jobs are running while your job is running.
However, you wouldn’t need to worry and the job would usually succeed as it retries the failed bundle up to 4 times in batch mode.
In our cases, there are about 40 million entities from Cloud Datastore to be migrated to BigQuery time partitioned tables, it actually helped by configuring ‘maxNumWorkers’ to be less and therefore, it seemed to reduce the data being processed in parallel and finished successfully without complaining the quota limits.
You can specify ‘maxNumWorkers’ as a pipeline job option. However, if it happens often and you feel that the quota limits would not be enough for your production usage, contact Google for inquiring dataflow custom quota limits.
Loading data into BigQuery instead of streaming them
A pipeline job will do streaming data into a BigQuery table if dynamic table name is used for sharded or time partitioned table. Because of that, it would be slow to migrate a large volume of data.
Using static table name guarantees to load data once into a BigQuery table and will be faster just like using BigQuery console to load the Cloud storage backup to the table. we have seen issues with BigQuery IO failures such as pipe broken and ssl error while doing streaming insert.
All the issues are gone now and worked well after we switched pipeline jobs to loading data into a BigQuery table instead of streaming insert.
Testing strategy with pipeline jobs
Dataflow sdk provides unit level testing utilities so that we can easily assert the pipeline steps. For example, creating static data in unit test can be easily done and the utilities can assert PCollection step by step in the pipeline.
However, integration tests with pipeline jobs running on Google Cloud Dataflow will be hard to be automated on build system as they need to use actual resources from various storages and need to be validated somehow after all.
Assuming that the testing strategy would be upon the complexity of pipeline jobs, most of pipeline jobs for data migration may not need automated tests since they usually consist of a few steps from source to sinks.
Instead, we could actually run the jobs often on testing environment with production like data during development so that we can validate the results and fix the logic accordingly.
Refer to Apache Beam testing guide for more details.
Final thoughts
We’ve come across some advantages of Google Cloud Dataflow for data migration such as:
- No-Ops for deployment and management
- Auto scaling for quick processing
- No longer gradual migration
- Connection between various storages
And have looked at lessons learnt from our experience so far.
Google Cloud Dataflow has given us a lot of relief from some old hacky ways of doing data migration and it is a great addition to our product and provides us with new ways of evolving our application architecture in GCP.
I hope that after reading this article you could get an idea of the benefits of Dataflow particularly for the case of data migration in GCP.
About the author:
Dan Lee is a software developer and has been with PaperCut Software in Melbourne since November 2015. He is from South Korea and he is passionate about learning and sharing new technologies and outside of work, likes to go camping with his family and friends.

