
After rolling out PaperCut Views on the Google Cloud Platform, we realised that the operation cost was more affected by the instance running time than by the number of IO operations, storage, cache, etc. In this article, I will show the problems we found in our original architecture and the changes we made to reduce the operation cost by reducing the instance running time, hoping that our experience could help other teams doing similar products on the GCP.
What is PaperCut Views?
PaperCut Views is our free printing analytics, insights and supply forecast product targeted to small and home offices.
It is hosted in the Google Cloud Platform (GCP) which is a great provider of cloud services, and particularly, it is running on AppEngine, their platform as a service. One of its big benefits for IoT applications such as PaperCut Views, is that it can auto scale horizontally, spinning up new instances as needed according to the load of the application.
Why did we want to refactor?
IoT applications generally have to deal with a lot of events. PaperCut Views at the moment of writing this article was receiving 1.7 million events per day thanks to the 75k registered printers. These numbers are growing around 15k new printers per month representing 300.000 events more per day. Given that this is a free product, we wanted to try and reduce the operation cost so that we could keep the same level of service to our growing customer base.
Our approach to cost reduction
The first natural approach to reduce costs would be to reduce the number of events per printer (which we did), but we soon realised that our architecture also needed to be improved. In the following sections I will show an overview of our initial architecture, the problems we found on it and the changes we made to reduce the costs.
Our initial architecture
The following is a simplified version of the moving parts of the architecture we had at launch time:
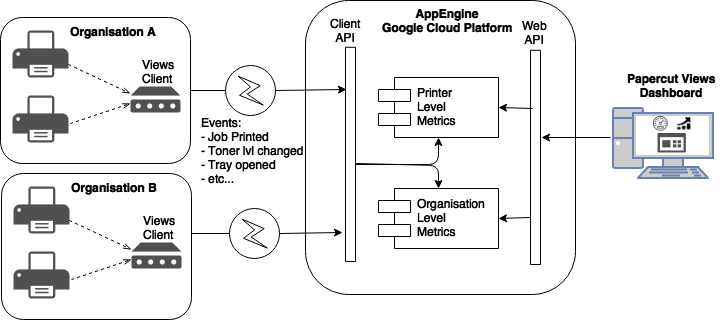
In the previous diagram, the clients are installed in our customer’s organisations to capture the information of the printers and send events such as job printed, toner level changed etc to the cloud. These events are processed by our cloud application which updates various metrics such as total pages printed per month, toner and paper forecast etc. The metrics are calculated organisation wide as well as per printer. Then, the users would be able to see the metrics via our web application.
When we went live, our design was oriented to limit the datastore operations per event, hoping that the reduced number of IO actions kept the costs low. Since we needed real time metrics in our dashboard, we decided to calculate them every time we received an event and store them on big datastore documents containing all of the metrics; one document for each organisation and one for each printer. Each document was fetched updated and saved once per event.

Soon after we went live, we realised that the cost was more affected by the AppEngine instances running time than by the IO or storage, so we started to plan the refactor.
Problem 1: High contention spots
As you can see, every time some action happened in any printer in an organisation, the two big documents were updated. This resulted in high contention spots in our storage, which despite we sharded the documents, it caused a lot of retries due to optimistic locking. In other words, if multiple events modify the documents inside a transaction at the same time, the first one to finish will commit, the others would need to retry. This kept the instance busy for a longer period of time trying to fetch, update and save a document since the whole cycle needed to be repeated until all events were calculated.
So, first refactor goal: Keep the storage high contention spots under control, even at the expense of duplicated data and more IO
The approach we took was to store some metrics in different documents. This implied more fetches per event but this also meant that the events that didn’t affect that particular metric, wouldn’t modify the document, therefore less contention and less retries caused by the optimistic locking errors.
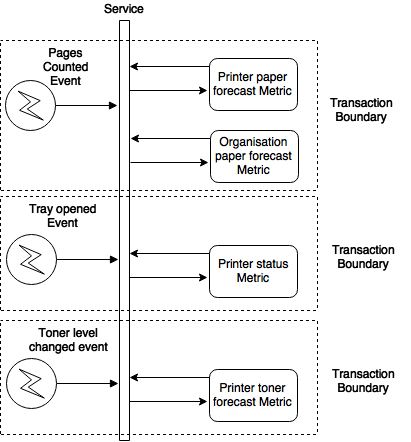
After doing this, we had less instances attending the same number of events. However, there were still some cases in which the processing time of an event was long.
Problem 2: Cross-group transactions
It was common that a single event would modify multiple metric documents. For that, we created a transaction around them to keep the modifications consistent (see paper forecast metrics in the previous diagram). Modifying multiple documents in GCP datastore generally* implies a cross-group transaction, which takes longer to commit increasing the chances of optimistic locking and again, more instance uptime.
Second refactor goal: Avoid modifying more than one document per transaction.
For this, we decided to adopt eventual consistency using domain events according to DDD principles. The idea is that the documents could be updated independently and asynchronously, achieving consistency after a short period of time. We rely on Google Pub/Sub for this, since it guarantees the delivery of the events among other things.
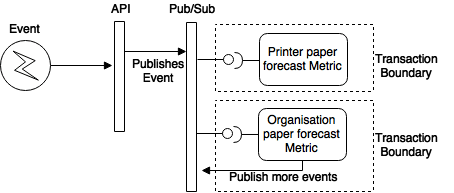
With this approach, the total instance time was reduced because the transactions were much faster and also because by modifying one document at a time we reduced the chances of contention. Until now, this has been the most effective change for us when it comes to cost reduction. As a side effect, we ended up with smaller documents and better segregated logic.
Problem 3: Big nested documents
At the beginning, when we decided to store all metrics related to an organisation in one document, we ended up with big nested structures with lots of data in them. Fetching this type of documents takes more time than fetching smaller documents, like for example, a document storing just a few user details.
Third refactor goal: Keep document size small.
This was a side effect of the previous two changes, and while it might not be critical by itself, when combined with reducing contention spots and eventual consistency can produce a significant reduction on instance time which again, is the most expensive item in our monthly invoice from google.
Is that all?
No, there are other areas that are worth checking. In our team, we are currently working on:
Reducing unnecessary liveliness: Do you really need all events to be processed on real time? For PaperCut Views, the answer is no. Some metrics can be recalculated daily or monthly.This would mean that events won’t be processed as they arrive but in batch at the end of the day.
We are currently streaming the events directly into BigQuery, the GCP Data warehouse, and we are working on calculating the non-real-time metrics directly out of there.
Splitting into multiple services: Views at this moment is mostly a monolith. Having multiple services will allow us to tune each instance type according to the kind of load they are handling and so, we will be able to assign less powerful and cheaper instances to the services that are not critical and bigger ones to the ones that process real time data.
Wrapping it up
After analysing the operation cost breakdown, we realised that IO operations are not as critical as instance running time in the GCP, particularly in AppEngine. We aimed our optimisations on reducing the processing time.
We focused our refactor in:
- Reducing the datastore contention spots by sharding, splitting the documents and/or duplicating data.
- Adopting eventual consistency to be able to store one kind of document per transaction.
- Keeping a small document size.
Being the second one the most effective so far for our case.
We are still working on improving PaperCut Views as well as designing some other exciting products that would take advantage of all of our learnings on the Google Cloud Platform. Our team has grown in size and diversity, so I am sure we will have a whole lot of stories and learnings to share.
Stay tuned and thank you for reading!
About the author:
Andres Castano is a senior developer and the team lead of PaperCut Views. He joined PaperCut 2 years ago and has been actively involved in the architecture and technical direction of the product. He comes from Colombia and in his free time he likes to go out for a run, play soccer and attend the different technical meetings happening in Melbourne.
Check out his personal blog at: https://afcastano.github.io or follow him on twitter @afcastano
