
At the heart of our day-to-day operations sits an application called PC-Internal. It’s the place where we process orders, store customer data, and generate licenses. Over the years, we’ve added quite a few features to cater for the ever-changing needs of our evolving business.
Nowadays, of course, there’s a wide choice of commercial off-the-shelf products that are tailored to the specific requirements of the different business functions. PC-Internal still remains the core system and our central data store, but we’re also gradually integrating with external systems. After all, working with Salesforce is not much fun, if you can’t see any customers in there.
To coordinate the synchronization, we started using Google Pub/Sub . Along the way, we encountered quite a few challenges and not everything went according to plan. In this post, I want to take a look back and share what we’ve learnt so far.
Our systems architecture
PC-Internal is a web application based on Spring. It runs on Google AppEngine and uses the Google Cloud SQL database. In order to make our code base more testable, maintainable and reusable, we’re moving towards a service-oriented architecture. New features are no longer added to PC-Internal itself. Instead we’ve given it a companion called PC-Internal API. This separate application hosts small and reusable REST services.
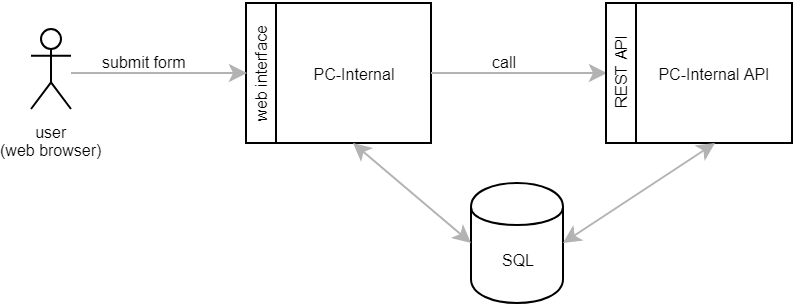
PC-Internal typically stores some data in the database and then calls one or more REST services. PC-Internal API retrieves the data from the database and carries out the requested operation.
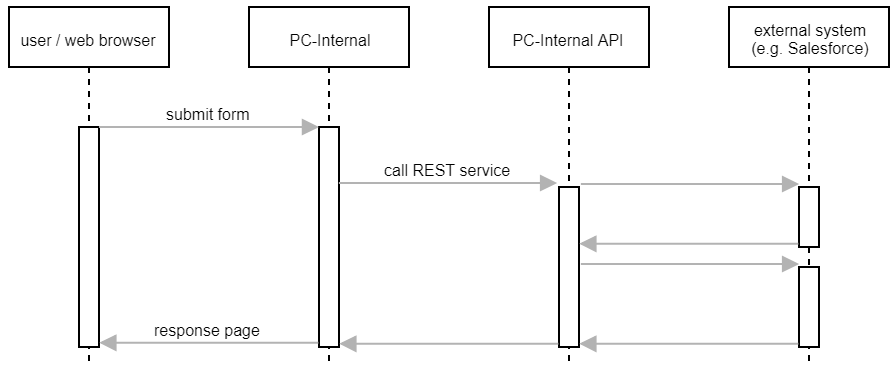
When integrating external systems, this approach is not ideal.
- The web-frontend becomes slow. Once the user has pushed the submit button, all external systems must be synchronised, before PC-Internal actually delivers the response page to the browser.
- Synchronisation failures are reflected back to the user. For example, if we can’t connect to an external system, the user will see an error message, even though the primary action (e.g. creating a customer in the database) might have succeeded.
- If a REST service call fails, PC-Internal might not be able roll back all actions it has already taken. This can cause data inconsistencies.
It’s obviously better to perform the synchronization asynchronously in the background and neither require the user nor PC-Internal to wait for the result or deal with errors.
Adding Pub/Sub to the mix
To decouple the integration of external systems, PC-Internal does not call the corresponding REST service directly. It rather publishes a Pub/Sub message, which is then asynchronously dispatched to and processed by PC-Internal API. Not all calls go through Pub/Sub, though. Most of our REST services perform only database operations. They are quick and rarely fail. These services are still called directly.
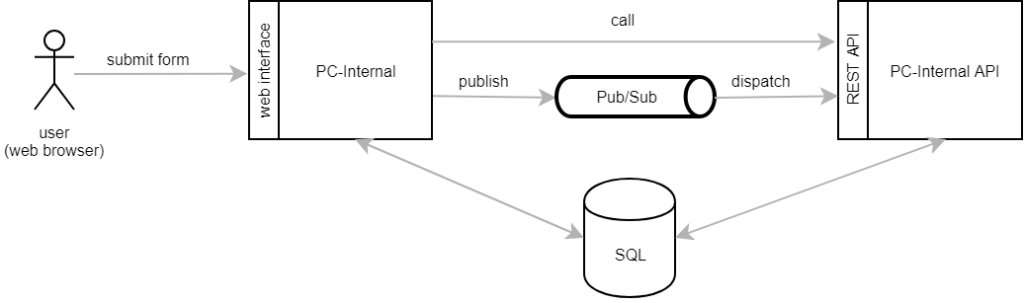
By publishing a Pub/Sub message, PC-Internal only schedules the synchronization but doesn’t have to wait for the message to be dispatched and processed.
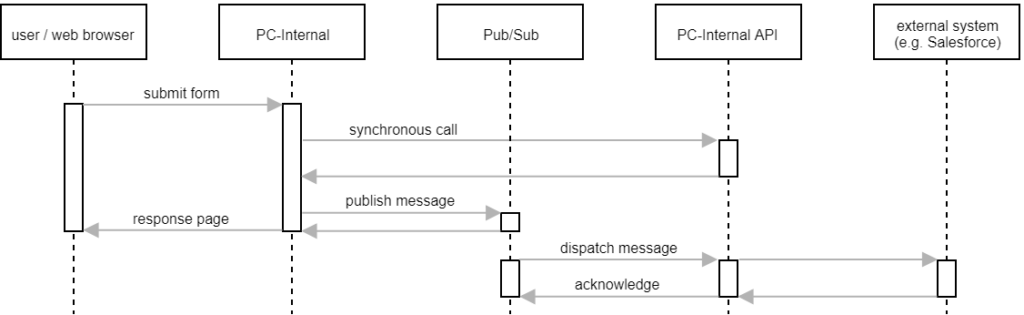
When triggering actions through Pub/Sub:
- the web browser receives the response page quicker
- the user is not affected by errors occurring while calling external systems
- in case of errors, Pub/Sub will retry to dispatch the message over and over again
- Pub/Sub applies load balancing, limiting the number of parallel external requests
Structuring the topics and subscriptions
We initially used Pub/Sub for “quote opportunities”. After issuing a quote through our order system, we wanted to create an opportunity in Salesforce. We set up a topic and added a handler (REST endpoint) in PC-Internal API.

However, the naming convention felt somehow odd and didn’t fit in with the bigger picture. We had planned to attach and remove event handlers dynamically as the system evolves, but our initial setup made that kind of impossible. The event was only published when PC-Internal needed to create an opportunity and the topic’s name implied what was going to happen in PC-Internal API. We eventually decided to only publish messages describing events that have already occurred, while defining the required actions implicitly by attaching event handlers.
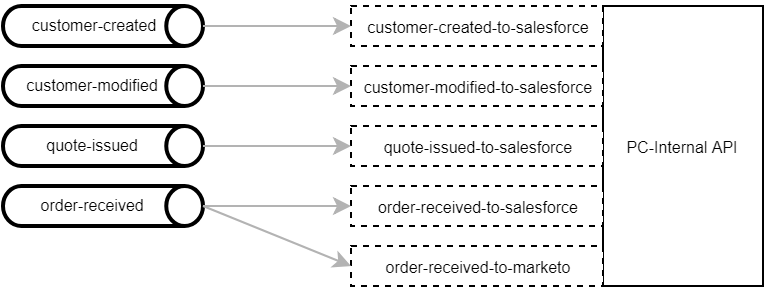
The JSON payload data sent through each topic looks different. A customer created event contains a customer number, while a quote issued event carries a quote number instead. We therefore needed separate handlers, even though some events are processed in very much the same way. However, the event handlers themselves are only the REST endpoints and the actual action is implemented in reusable components.
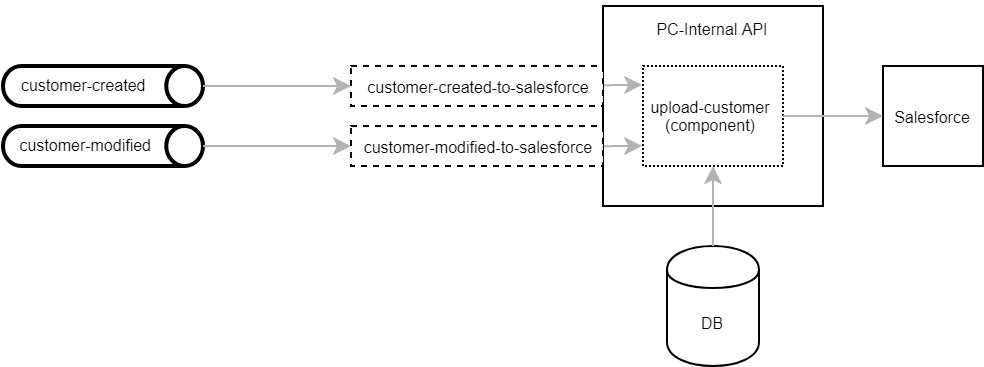
In the above example, the customer-related Salesforce event handlers only need to extract the customer number from the Pub/Sub message and pass it on to the corresponding component.
Securing the endpoints
PC-Internal API is a Spring Boot application. Whenever a REST service is called, the request must contain a valid JWT bearer token. It contains the username, the permissions and an expiry date. This information is digitally signed and encoded. When processing a request, we decode the token, verify the signature, make sure that it hasn’t expired yet and check the user’s permissions.

Before calling a REST service, PC-Internal creates a short-lived JWT bearer token, which is stored in the HTTP authorisation header and transmitted through a secure TLS connection.

Unfortunately, this mechanism is not supported by Pub/Sub. We use “push subscriptions” where we configure the URLs of REST endpoints as subscribers. Pub/Sub manages the whole dispatching process and posts the messages’ payload data to these endpoints. The requests do not include any authorisation header. The endpoints therefore need to be public services. To protect them, it is recommended to add a hard-coded form of authentication as a query parameter to the URL.

This, however, is more of a workaround. If someone gains access to the Google Cloud Console, they could obtain the URL and subsequently call the REST service with no questions asked. Unlike the JWT bearer tokens, the hard-coded password does not expire. Moreover, PC-Internal API would be unable to check permissions, as we don’t know which user actually triggered the event. To not undermine our security measures, we eventually decided to pass the bearer token as part of the body payload data.

We still add a query parameter to indicate that the request comes from Pub/Sub. This activates a second Spring authentication filter that retrieves the token from the payload data.
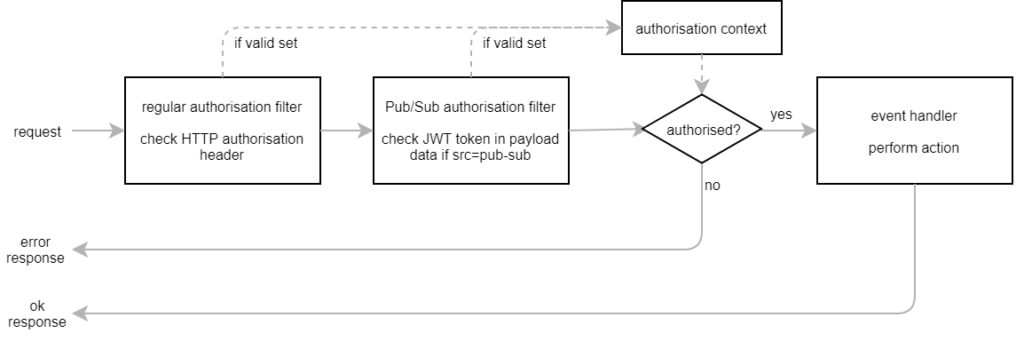
If none of the filters find a valid JWT bearer token, the REST request is rejected with an HTTP unauthorised error response.
Managing permissions
Most of the REST services in PC-Internal API can only be invoked if the caller has the respective permission. When performing additional actions in the background, this approach reaches its limits.
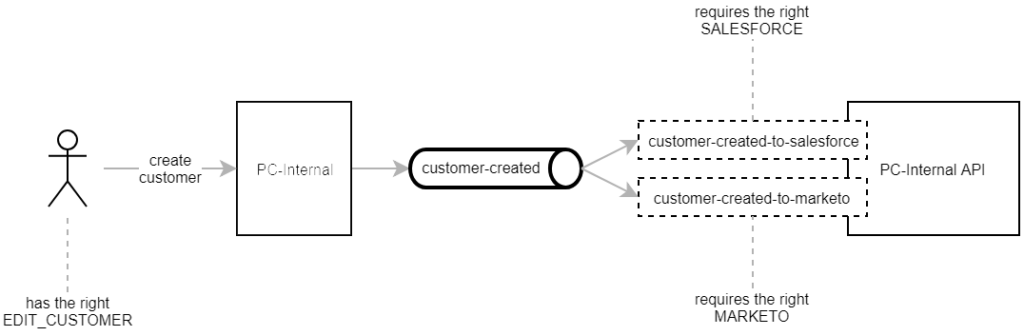
In the above example, the user has the right to create a customer in PC-Internal. However, the resulting “customer created” event subsequently requires permissions to access Salesforce and Marketo. Usually the user neither does nor should have these permissions and is often even unaware of what’s happening in the background. We eventually decided to effectively grant all permissions to Pub/Sub messages.
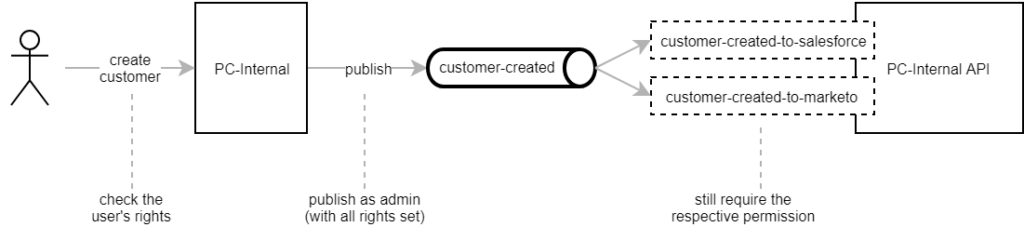
We only check the user’s permission for the direct action they are performing. When PC-Internal creates a Pub/Sub message in the background, it is published with an admin JWT bearer token. This allows the event to be processed independent of the user’s rights. At the same time, the event handlers remain restricted and can’t be called by a user directly unless they have the necessary permission.
Dealing with errors
When PC-Internal publishes a message, it assumes that it will eventually be processed successfully. We therefore have to make sure to spot and deal with errors that occur in the event handlers. For example, we sometimes fail to connect to external systems. Our REST service then returns an HTTP error code, causing Pub/Sub to re-dispatch the message for up to one week. After that, it will eventually be discarded.
We generally didn’t want messages to loop for days, unless there was a significant likelihood of them succeeding eventually. We therefore classified potential errors as either temporary or permanent. Every exception is considered permanent by default. Instead of going into the Pub/Sub retry loop, messages that suffer from permanent exceptions are discarded and brought to our attention for manual intervention.
On the other hand, temporary exceptions should have retries. Being unable to log in to Salesforce, for example, is usually down to an expired password or a locked account. After resetting the password or unlocking the account, messages can be processed successfully. Keeping the affected messages in Pub/Sub’s retry loop frees us from having to deal with them manually.
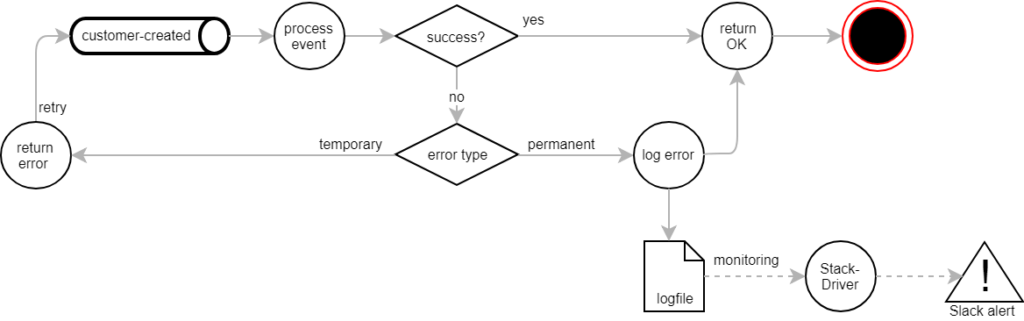
Whenever a permanent error occurs, we discard the Pub/Sub message and write the error to the log file. From there it is picked up by the StackDriver monitoring, which eventually sends us a notification via Slack.We can then analyse the problem and possibly republish the discarded message manually.
With this in setup we thought to have everything covered, but not all went according to plan…
Problem 1: Race conditions
We initially used Pub/Sub for “quote opportunities”. When a customer requested a quote, we inserted it into the database and published a Pub/Sub event. PC-Internal API would then read the request from the database and create an opportunity in Salesforce. What we didn’t anticipate was, that the Pub/Sub event was published, dispatched and processed before the database transaction was committed. PC-Internal API subsequently failed to load the quote request from the database.

PC-Internal API classified this as a permanent exception. It logged the error and discarded the message to prevent further retries. StackDriver sent us an alert on Slack and we had to manually republish the Pub/Sub message. This was obviously an unnecessary nuisance. We quickly changed the implementation in PC-Internal to make sure that the database transaction was committed before publishing an event. This solved the problem, but there might still be other situations in which race conditions occur. In order to deal with them as well, we introduced the concept of a short enforced retry loop.

When the processing of an event fails, it is returned to Pub/Sub to schedule a retry. This is done repeatedly for five minutes starting from when the event was dispatched for the first time. After that period, the message is discarded, logged as an error and dealt with manually. The five-minute limit does not apply to temporary exceptions, though. They go through the retry-cycle for a whole week.
Problem 2: Unsuitable JWT bearer tokens
Our next challenge were failing authentications. Instead of publishing Pub/Sub messages as an admin user, we sometimes accidentally published them under the real user’s account. The JWT bearer token had too few permissions and didn’t make it through our authentication filter.

There was a problem with our admin JWT bearer tokens as well: They were too short-lived and remained valid for only one hour. Usually that’s more than enough, but sometimes it isn’t. At some point we identified a bug in our event handler and had to suspend the Pub/Sub subscription. After deploying a hotfix we reactivated it and expected the Pub/Sub messages accumulated in the meantime to be processed. But since the JWT bearer tokens had already expired, they didn’t make it through the authentication filter either.

Both problems were solved by ensuring to always publish messages with long-lived admin JWT bearer tokens that are valid for at least one week. But there might still be cases where the authentication fails. With the above implementation the effect is quite dramatic. Pub/Sub dispatches a message, receives an unauthorised error as response and schedules a retry. The retry will fail as well and trigger yet another attempt. The message will be dispatched for 1 week at a rate of up to one attempt per second. This is obviously not great, because…
- it clogs up the whole event system
- the retries put unnecessary load on the subscriber endpoints
- it reduces the overall Pub/Sub throughput, delaying authorized messages as well
Luckily, there’s a simple solution to this problem: remove unauthorized messages from the queue immediately.

Under normal circumstances, we should not see any unauthorised requests. If one comes up nevertheless, we just log and discard it. A Slack alert triggered via StackDriver brings the issue to our attention so that we can analyse and fix the root cause.
Problem 3: Misclassified exceptions
PC-Internal has a few fields for email addresses. Each one is meant to store one address only, but people occasionally put in more than that. Trying to upload such a field to Salesforce causes an HTTP bad request response. We accidentally classified this error as a temporary exception. The message was kept in the retry loop for a whole week, despite not having any chance of being processed successfully.

We only had a handful of of these cases, but within a few days we saw more than 150,000 Salesforce synchronisation attempts. This not only caused unnecessary load on our system, but also wasted quite a big portion of our Salesforce API quota. The intermediate fix was to reclassify these exceptions as permanent. The messages are still kept in the retry loop for a while, but are discarded eventually after five minutes. And of course we had to fix the root cause by transforming data to comply with the target system’s constraints.
Putting it all together
With all these lessons learned (the hard way), we ended up with the following architecture:

For us it works well to stick to the these rules:
- Publish messages with a long-lived admin JWT bearer token to prevent processing errors due to missing permissions and expired authentications
- Discard unauthorised messages straight away and do not allow them to enter the retry loop
- For all other failures, always retry for a few minutes before giving up - it might be a race condition that heals itself
- Keep temporary exceptions in the retry loop indefinitely (but make sure to have some monitoring in place to spot and fix issues that require attention)
- Be vigilant as to which exceptions you classify as temporary - retrying a bound-to-fail message every second for a week can cause a lot of unnecessary load
- Make sure that each discarded message is brought to your attention for root cause analysis and manual cleanup
What’s been your Pub/Sub experience? Got any tips you want to share? Any questions that I might be able to help you with? Let me know in the comments below.
